https://colab.research.google.com/drive/1803kaOppAP_KP3ffpL9GG3n3EcgT00Q-?usp=sharing
주식가격예측_regression.ipynb
Colab notebook
colab.research.google.com
과거의 주가 데이터를 가지고 미래의 주가를 예측하는 Regression Model을 만들 수 있을까?
요즘 핫하다는 머신러닝을 이용하여 주가 예측 모델을 개발해 보자!!
(아 물론 과제이긴 하지만 데이터만 주어지고 나의 노력과 고뇌가 많이 들어간 사실상 나만의 프로젝트라고 할 수 있다...)
사용한 데이터:
Data: (2023.07.03 ~ 2023.12.22의 주식 데이터) (*cp949로 csv 파일 인코딩하여 로드)
- stock_list.csv (종목 리스트) – 364 rows x 3 cols
- stock_values_linear.csv (linear regression을 위한 주가 정보) – 364 rows x 125 cols
- stock_values_logistic.csv (logistic regression을 위한 주 정보) – 364 rows x 125 cols
Stock_list에 있는 주식 중 무작위로 고른 3개의 주가을 예측할 것이다.
학습 데이터 분리
주어진 데이터는 월~금 * 25주이다.
여기서 나는 생각한다 어떻게 모델을 학습시킬 것인가...
문득 떠오른 아이디어는 이번주 주가 [i:i+5]이 주어지고 다음 주 주 [i+5:i+10]으로 한다.
그리고 마지막 test에는 제일 마지막 5일 만을 사용한다.
총 24주를 학습에 사용하고 마지막 1주를 테스트에 사용하도록 하겠다.
시작
시작에 앞서 개발환경은 google colab이다.
1. 필요한 라이브러리 설치
!pip install matplotlib
!pip install pandas numpy scikit-learn matplotlib
2. 데이터 로딩, 라이브러리 임포트
# 라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 데이터 로딩
# CP949 인코딩을 사용하여 csv 파일 로드
stock_list = pd.read_csv('stock_list.csv', encoding='cp949')
stock_values_linear = pd.read_csv('stock_values_linear.csv', encoding='cp949')
stock_values_logistic = pd.read_csv('stock_values_logistic.csv', encoding='cp949')
3. 데이터 분리, 모델 학습, 성능평가(mse), 데이터 시각화(plot)
# 주식 리스트에서 3개의 주식 종목 코드를 선택
sample_stocks = stock_list['종목코드'].sample(3).values
def predict_next_week_prices(stock_code):
# 종목코드를 보고 종목이름 알기
stock_name = stock_list[stock_list['종목코드'] == stock_code]['종목명'].iloc[0]
stock_type = stock_list[stock_list['종목코드'] == stock_code]['상장시장'].iloc[0]
data = stock_values_linear[stock_values_linear['종목코드'] == stock_code].iloc[:, 1:].values.flatten()
X = []
y = []
for i in range(0, len(data) - 5, 5): # i를 10씩 증가시키며 반복
X.append(data[i:i+5]) # 이번 주 데이터 (월요일부터 금요일까지)
y.append(data[i+5:i+10]) # 다음 주 데이터 (월요일부터 금요일까지)
X = np.array(X)
y = np.array(y)
# 훈련 데이터와 테스트 데이터 분할
X_train = X[:23] # 처음 120개, 23주치
y_train = y[:23] # 처음 120개, 23주치
X_test = X[23:] # 마지막 5개
y_test = y[23:] # 마지막 5개
# 선형 회귀 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"{stock_type} {stock_name}의 다음 주 주가예측모델 평가 MSE: {mse}")
# 예측 결과와 실제 데이터 시각화 (다음 주 월요일부터 금요일까지)
plt.figure(figsize=(10, 5))
days = ["Mon", "Tue", "Wed", "Thu", "Fri"]
# 테스트 세트에 대한 첫 번째 예측 주와 실제 데이터 선택
y_pred_first_week = y_pred[0] # 첫 번째 예측된 주
y_test_first_week = y_test[0] # 첫 번째 실제 주
x_ticks = np.arange(5) # 다음 주의 요일 수 (월~금)
# 예측된 데이터 플롯
plt.plot(x_ticks, y_pred_first_week, label='Predicted', marker='o')
# 실제 데이터 플롯
plt.plot(x_ticks, y_test_first_week, label='Actual', marker='x', linestyle='--')
plt.xticks(x_ticks, days, rotation=45) # 월요일부터 금요일까지의 라벨
plt.title(f"Next Week Prediction vs Actual for Stock Code {stock_code}")
plt.legend()
plt.show()
# sample_stocks는 예측을 수행할 종목 코드 리스트입니다.
for code in sample_stocks:
predict_next_week_prices(code)
결과
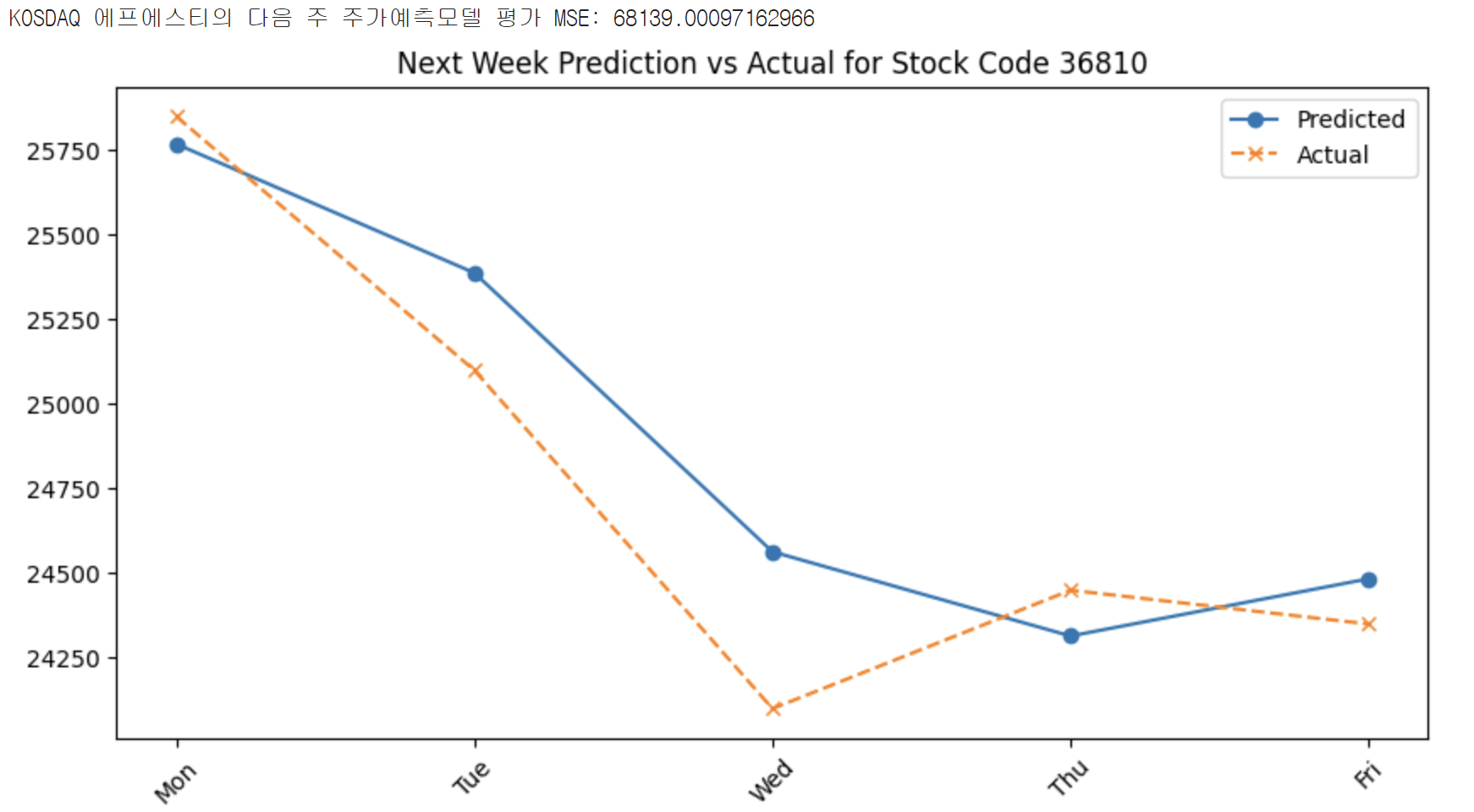
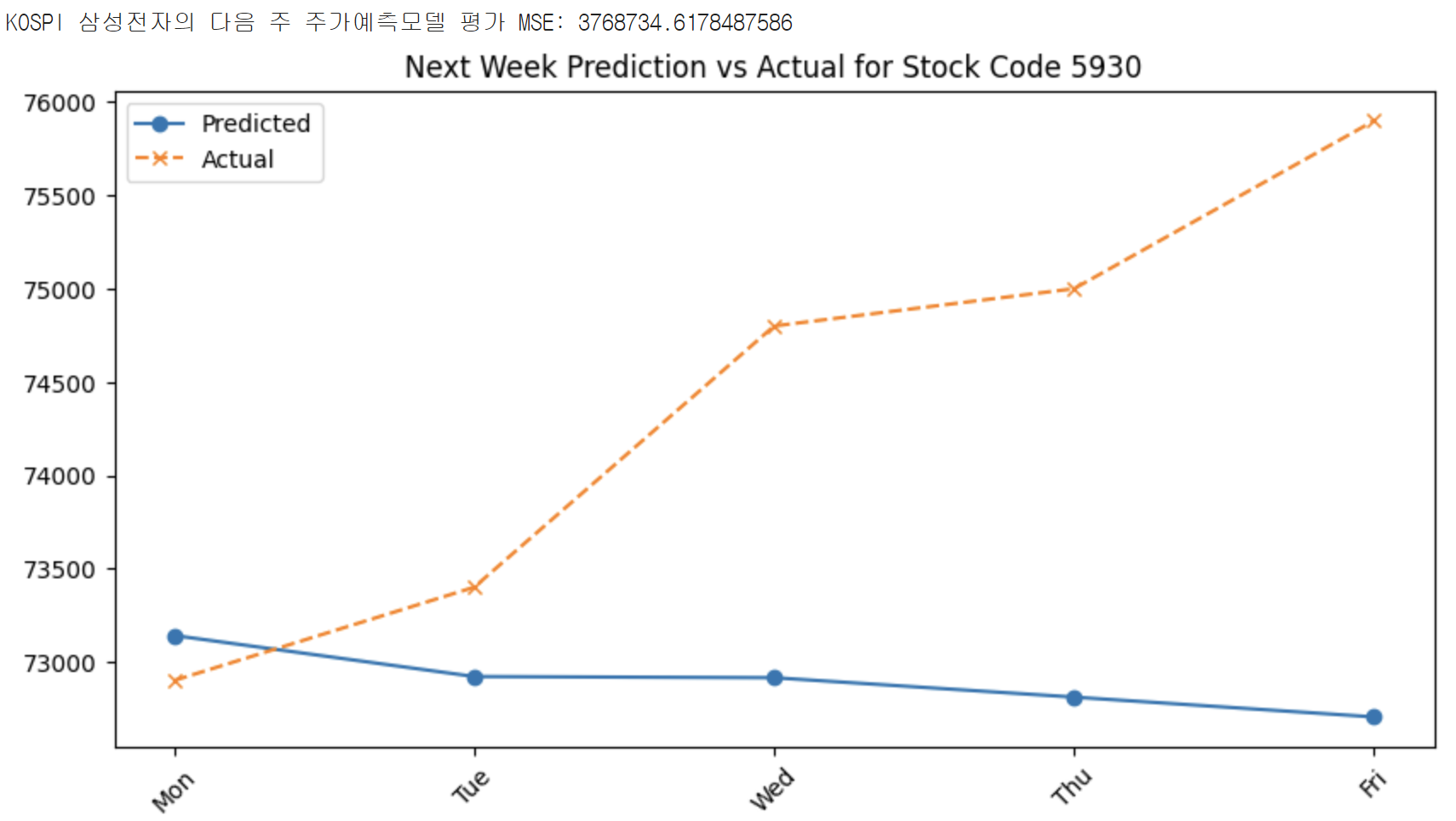
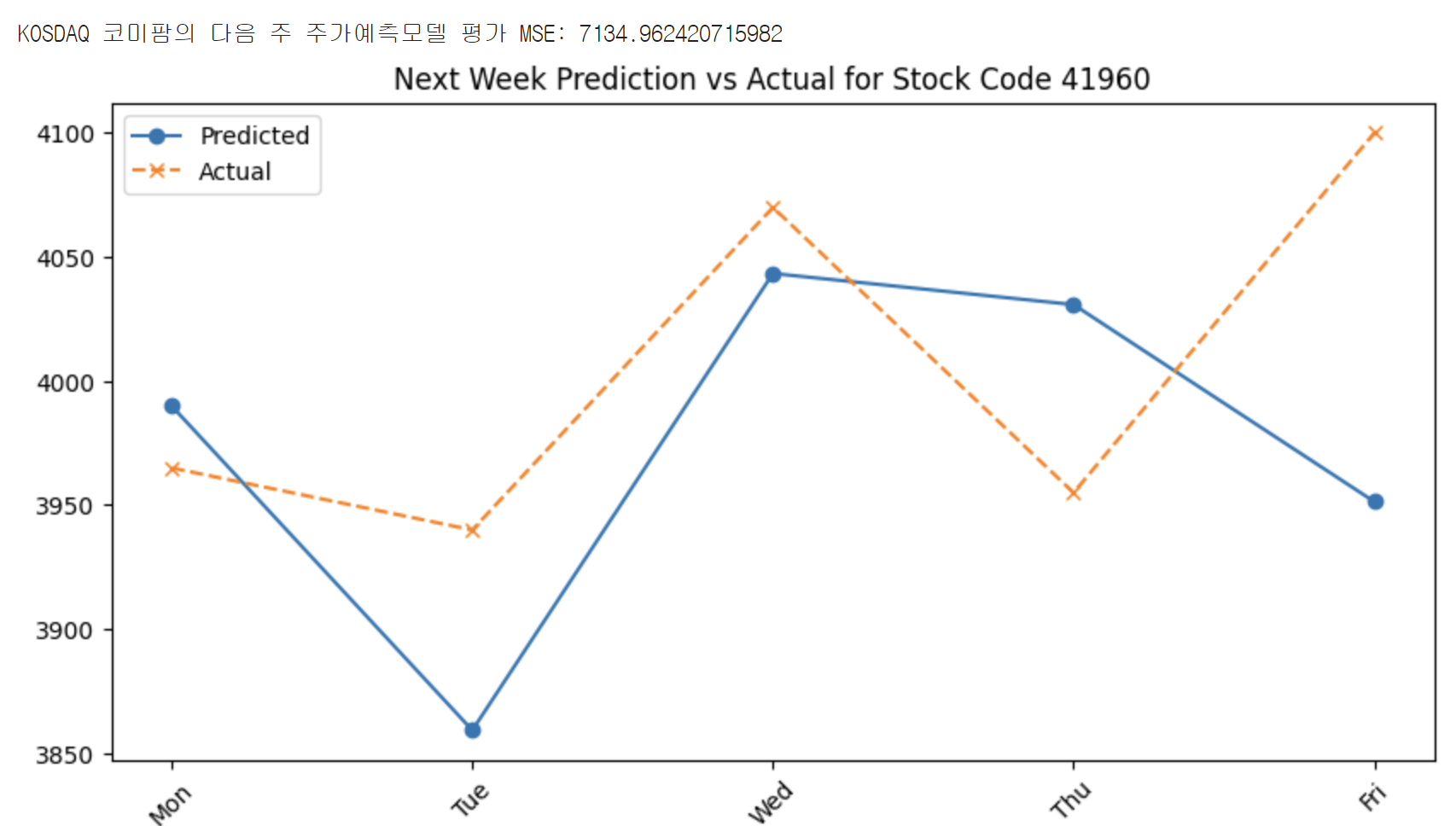
4. 추가 (Logistic Regression Model)
sample_stocks = stock_list['종목코드'].sample(3).values
def predict_next_week_trend(stock_code):
stock_name = stock_list[stock_list['종목코드'] == stock_code]['종목명'].iloc[0]
stock_type = stock_list[stock_list['종목코드'] == stock_code]['상장시장'].iloc[0]
# 주가 정보 추출
data = stock_values_logistic[stock_values_logistic['종목코드'] == stock_code].iloc[:, 1:].values.flatten()
X = []
y = []
for i in range(0, len(data) - 6, 5):
X.append(data[i:i+5]) # 이번 주 데이터 추가
y.append([data[i+6]]) # 다음주 월요일 데이터 추가
X = np.array(X)
y = np.array(y)
# 데이터 분리
X_train = X[:23]
y_train = y[:23].ravel()
X_test = X[23:]
y_test = y[23:].ravel()
# 로지스틱 회귀 모델 학습
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"{stock_type} {stock_name}의 다음주 주가추세예측모델 정확도: {accuracy}")
# 실제 값과 예측 값 비교 시각화
plt.figure(figsize=(10, 5))
plt.plot(y_test, 'x', label='Actual Trend') # 점으로 표시
plt.plot(y_pred, 'o', label='Predicted Trend', linestyle='None')
plt.title(f"Stock Code {stock_code} Trend Prediction")
x_ticks = np.arange(1)
days = ["Next_Mon"]
plt.xticks(x_ticks, days, rotation=45)
plt.legend()
plt.show()
return accuracy
accur = 0.0
# 3개 종목에 대해 추세 예측 실행
for code in sample_stocks:
accur += predict_next_week_trend(code)
num = int(accur)
if num < 3:
print(f"적중률 = {num}/3")
else:
print(f"적중률 = 1")
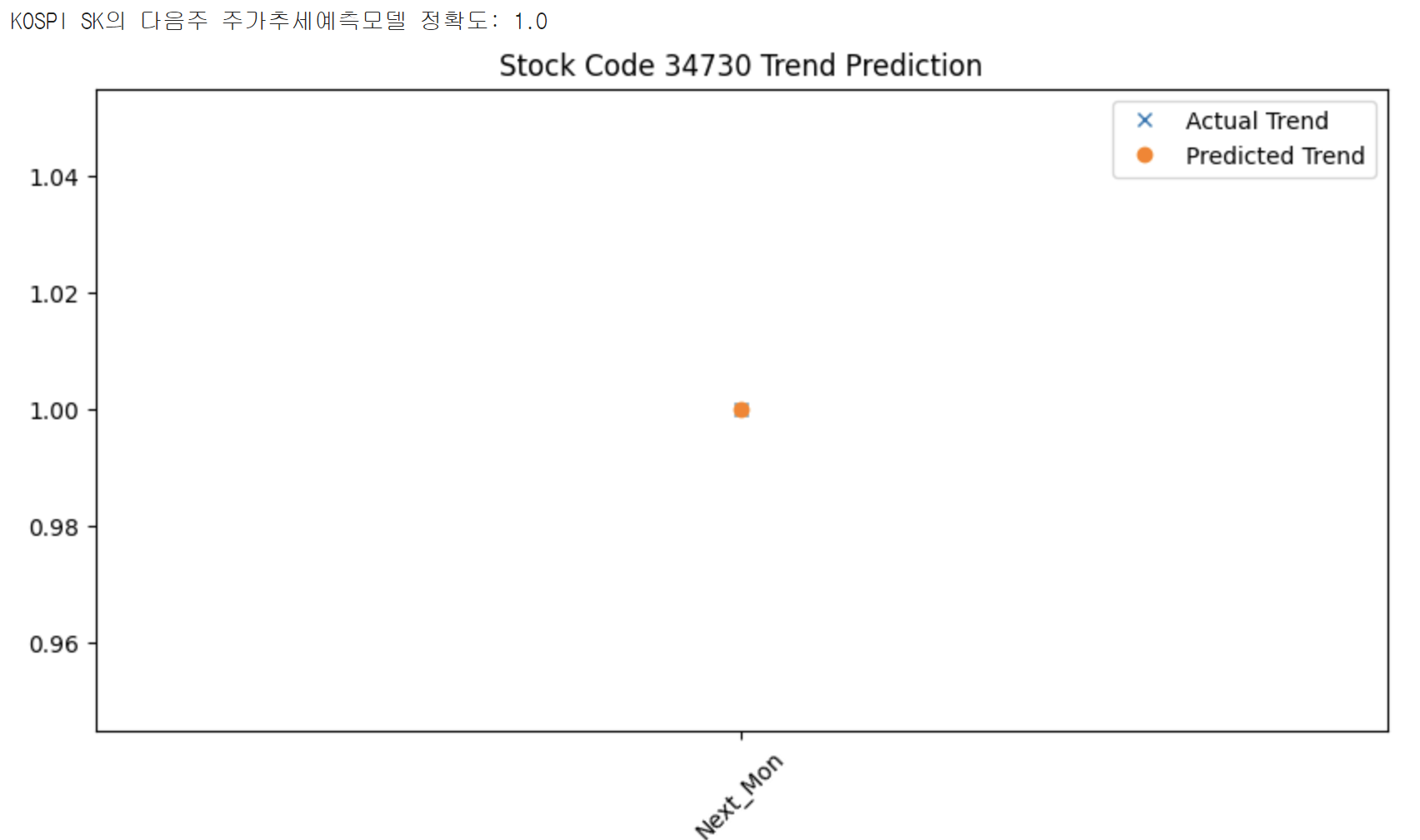
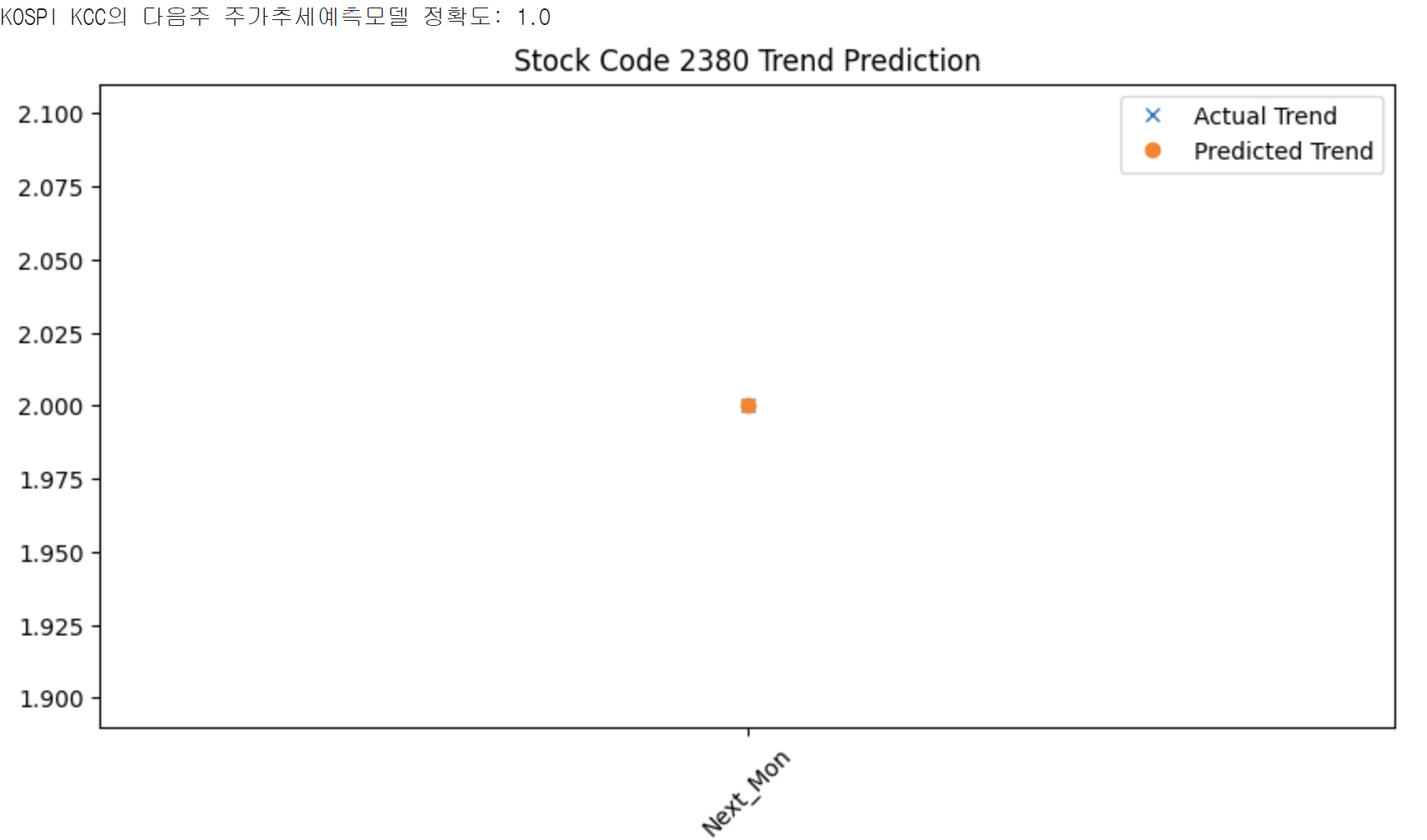
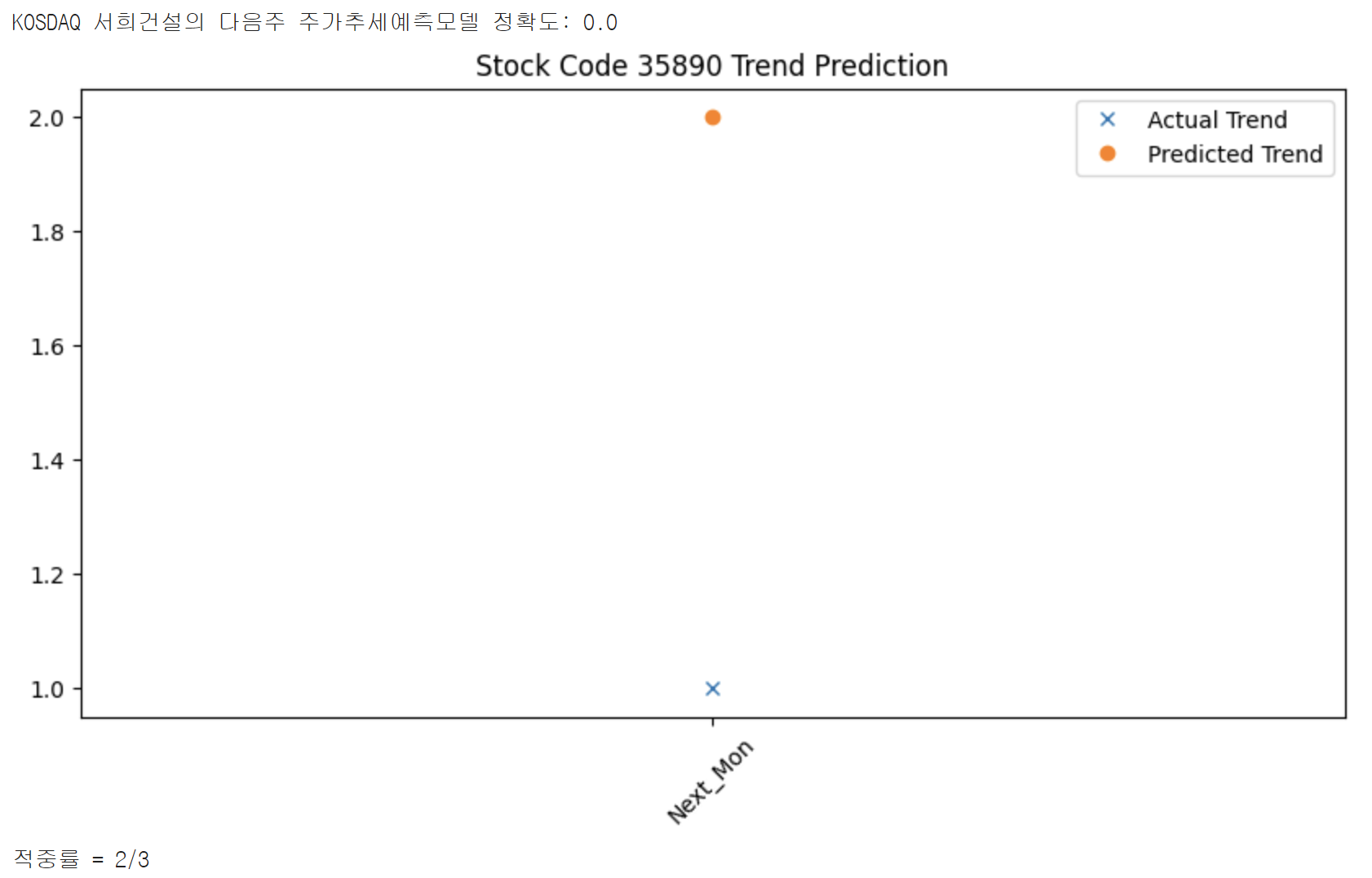
이는 Logistic Regression Model을 사용해 보기 위해 간단하게 해 본 예측이다.
결과는 상당히 처참(?)하다. 머신러닝에서는 평가하는 방법도 중요하다. 앞으로의 모델의 수정과 발전방향을 알 수 있기 때문이다. 하지만 이런 accuracy score는 너무나 직관적이다. 그냥 알 수 있는 정보이다. 딱히 중요하지 않은 정보이기 때문에 잘 사용되지는 않을 것 같다.
로지스틱의 경우에는 처음엔 앞의 5일을 바탕으로 다음 주 5일을 전부 예측하는 방법으로 가려고 했지만 선형회귀랑 다를 게 없어 보여 그렇다면 다음 주의 전체 추세를 평균으로 해서 예측하려고 했지만 그 또한 성능이 안 좋게 나오기에 다음 주 월요일의 데이터만 추가하는 것으로 했습니다.
느낀 점
이 프로젝트를 해보면서 느낀 점이 있다. 물론 과제라서 어쩔 수 없이 시작했지만 다른 과제와 달리 제약조건이 현저히 적었고 나의 자율성에 맡기는 과제였기에 다른 과제에 비해 더 열심히 했던 것 같다.
mse는 mean squared error의 약어로 각 예측값과 실제값의 차이의 제곱을 하여 나타낸 쉽게 말해 오차를 숫자로 보여주는 것이다. mse가 작을수록 모델이 더 정확한 것이다. 세 번째 경우는 mse가 7134로 여러 번 예측을 해봤을 때 굉장히 낮은 숫자가 나왔다!!
물론 이 모델이 실제로 효과가 있을지는 미지수다. 주식은 굉장히 많은 요인이 영향을 미치기 때문이다.
이런 단순한 지표로는 물론 추세나 과거의 오랜, 방대한 데이터를 학습시킨다면 분명 연관성이 있겠지만, 이 모델이 실제 주식시장에서는 사용되기 힘들 것이다. 하지만 만들어 봤다는 것에 의의를 두도록 하겠다.
만약 데이터가 더 많이 주어졌다면 훨씬 더 정확한 모델을 만들 수 있었을 것 같다.. 아쉬움이 많이 남는다.
이런 모델을 다른 사람의 도움 없이 스스로 만들 수 있었다는 것에 스스로 멋있다고 생각한다.
이런 간단하지만 스스로 뿌듯했던 과제는 프로젝트 카테고리에 남겨두도록 하겠다!
'프로젝트 > 머신러닝 과제' 카테고리의 다른 글
| [ML Project] Clustering, Regularization (0) | 2024.08.25 |
|---|---|
| [ML Project] EDA 데이터 분석 with SVM, PM, Decision Tree (2) | 2024.04.25 |
https://colab.research.google.com/drive/1803kaOppAP_KP3ffpL9GG3n3EcgT00Q-?usp=sharing
주식가격예측_regression.ipynb
Colab notebook
colab.research.google.com
과거의 주가 데이터를 가지고 미래의 주가를 예측하는 Regression Model을 만들 수 있을까?
요즘 핫하다는 머신러닝을 이용하여 주가 예측 모델을 개발해 보자!!
(아 물론 과제이긴 하지만 데이터만 주어지고 나의 노력과 고뇌가 많이 들어간 사실상 나만의 프로젝트라고 할 수 있다...)
사용한 데이터:
Data: (2023.07.03 ~ 2023.12.22의 주식 데이터) (*cp949로 csv 파일 인코딩하여 로드)
- stock_list.csv (종목 리스트) – 364 rows x 3 cols
- stock_values_linear.csv (linear regression을 위한 주가 정보) – 364 rows x 125 cols
- stock_values_logistic.csv (logistic regression을 위한 주 정보) – 364 rows x 125 cols
Stock_list에 있는 주식 중 무작위로 고른 3개의 주가을 예측할 것이다.
학습 데이터 분리
주어진 데이터는 월~금 * 25주이다.
여기서 나는 생각한다 어떻게 모델을 학습시킬 것인가...
문득 떠오른 아이디어는 이번주 주가 [i:i+5]이 주어지고 다음 주 주 [i+5:i+10]으로 한다.
그리고 마지막 test에는 제일 마지막 5일 만을 사용한다.
총 24주를 학습에 사용하고 마지막 1주를 테스트에 사용하도록 하겠다.
시작
시작에 앞서 개발환경은 google colab이다.
1. 필요한 라이브러리 설치
!pip install matplotlib
!pip install pandas numpy scikit-learn matplotlib
2. 데이터 로딩, 라이브러리 임포트
# 라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 데이터 로딩
# CP949 인코딩을 사용하여 csv 파일 로드
stock_list = pd.read_csv('stock_list.csv', encoding='cp949')
stock_values_linear = pd.read_csv('stock_values_linear.csv', encoding='cp949')
stock_values_logistic = pd.read_csv('stock_values_logistic.csv', encoding='cp949')
3. 데이터 분리, 모델 학습, 성능평가(mse), 데이터 시각화(plot)
# 주식 리스트에서 3개의 주식 종목 코드를 선택
sample_stocks = stock_list['종목코드'].sample(3).values
def predict_next_week_prices(stock_code):
# 종목코드를 보고 종목이름 알기
stock_name = stock_list[stock_list['종목코드'] == stock_code]['종목명'].iloc[0]
stock_type = stock_list[stock_list['종목코드'] == stock_code]['상장시장'].iloc[0]
data = stock_values_linear[stock_values_linear['종목코드'] == stock_code].iloc[:, 1:].values.flatten()
X = []
y = []
for i in range(0, len(data) - 5, 5): # i를 10씩 증가시키며 반복
X.append(data[i:i+5]) # 이번 주 데이터 (월요일부터 금요일까지)
y.append(data[i+5:i+10]) # 다음 주 데이터 (월요일부터 금요일까지)
X = np.array(X)
y = np.array(y)
# 훈련 데이터와 테스트 데이터 분할
X_train = X[:23] # 처음 120개, 23주치
y_train = y[:23] # 처음 120개, 23주치
X_test = X[23:] # 마지막 5개
y_test = y[23:] # 마지막 5개
# 선형 회귀 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"{stock_type} {stock_name}의 다음 주 주가예측모델 평가 MSE: {mse}")
# 예측 결과와 실제 데이터 시각화 (다음 주 월요일부터 금요일까지)
plt.figure(figsize=(10, 5))
days = ["Mon", "Tue", "Wed", "Thu", "Fri"]
# 테스트 세트에 대한 첫 번째 예측 주와 실제 데이터 선택
y_pred_first_week = y_pred[0] # 첫 번째 예측된 주
y_test_first_week = y_test[0] # 첫 번째 실제 주
x_ticks = np.arange(5) # 다음 주의 요일 수 (월~금)
# 예측된 데이터 플롯
plt.plot(x_ticks, y_pred_first_week, label='Predicted', marker='o')
# 실제 데이터 플롯
plt.plot(x_ticks, y_test_first_week, label='Actual', marker='x', linestyle='--')
plt.xticks(x_ticks, days, rotation=45) # 월요일부터 금요일까지의 라벨
plt.title(f"Next Week Prediction vs Actual for Stock Code {stock_code}")
plt.legend()
plt.show()
# sample_stocks는 예측을 수행할 종목 코드 리스트입니다.
for code in sample_stocks:
predict_next_week_prices(code)
결과
4. 추가 (Logistic Regression Model)
sample_stocks = stock_list['종목코드'].sample(3).values
def predict_next_week_trend(stock_code):
stock_name = stock_list[stock_list['종목코드'] == stock_code]['종목명'].iloc[0]
stock_type = stock_list[stock_list['종목코드'] == stock_code]['상장시장'].iloc[0]
# 주가 정보 추출
data = stock_values_logistic[stock_values_logistic['종목코드'] == stock_code].iloc[:, 1:].values.flatten()
X = []
y = []
for i in range(0, len(data) - 6, 5):
X.append(data[i:i+5]) # 이번 주 데이터 추가
y.append([data[i+6]]) # 다음주 월요일 데이터 추가
X = np.array(X)
y = np.array(y)
# 데이터 분리
X_train = X[:23]
y_train = y[:23].ravel()
X_test = X[23:]
y_test = y[23:].ravel()
# 로지스틱 회귀 모델 학습
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"{stock_type} {stock_name}의 다음주 주가추세예측모델 정확도: {accuracy}")
# 실제 값과 예측 값 비교 시각화
plt.figure(figsize=(10, 5))
plt.plot(y_test, 'x', label='Actual Trend') # 점으로 표시
plt.plot(y_pred, 'o', label='Predicted Trend', linestyle='None')
plt.title(f"Stock Code {stock_code} Trend Prediction")
x_ticks = np.arange(1)
days = ["Next_Mon"]
plt.xticks(x_ticks, days, rotation=45)
plt.legend()
plt.show()
return accuracy
accur = 0.0
# 3개 종목에 대해 추세 예측 실행
for code in sample_stocks:
accur += predict_next_week_trend(code)
num = int(accur)
if num < 3:
print(f"적중률 = {num}/3")
else:
print(f"적중률 = 1")
이는 Logistic Regression Model을 사용해 보기 위해 간단하게 해 본 예측이다.
결과는 상당히 처참(?)하다. 머신러닝에서는 평가하는 방법도 중요하다. 앞으로의 모델의 수정과 발전방향을 알 수 있기 때문이다. 하지만 이런 accuracy score는 너무나 직관적이다. 그냥 알 수 있는 정보이다. 딱히 중요하지 않은 정보이기 때문에 잘 사용되지는 않을 것 같다.
로지스틱의 경우에는 처음엔 앞의 5일을 바탕으로 다음 주 5일을 전부 예측하는 방법으로 가려고 했지만 선형회귀랑 다를 게 없어 보여 그렇다면 다음 주의 전체 추세를 평균으로 해서 예측하려고 했지만 그 또한 성능이 안 좋게 나오기에 다음 주 월요일의 데이터만 추가하는 것으로 했습니다.
느낀 점
이 프로젝트를 해보면서 느낀 점이 있다. 물론 과제라서 어쩔 수 없이 시작했지만 다른 과제와 달리 제약조건이 현저히 적었고 나의 자율성에 맡기는 과제였기에 다른 과제에 비해 더 열심히 했던 것 같다.
mse는 mean squared error의 약어로 각 예측값과 실제값의 차이의 제곱을 하여 나타낸 쉽게 말해 오차를 숫자로 보여주는 것이다. mse가 작을수록 모델이 더 정확한 것이다. 세 번째 경우는 mse가 7134로 여러 번 예측을 해봤을 때 굉장히 낮은 숫자가 나왔다!!
물론 이 모델이 실제로 효과가 있을지는 미지수다. 주식은 굉장히 많은 요인이 영향을 미치기 때문이다.
이런 단순한 지표로는 물론 추세나 과거의 오랜, 방대한 데이터를 학습시킨다면 분명 연관성이 있겠지만, 이 모델이 실제 주식시장에서는 사용되기 힘들 것이다. 하지만 만들어 봤다는 것에 의의를 두도록 하겠다.
만약 데이터가 더 많이 주어졌다면 훨씬 더 정확한 모델을 만들 수 있었을 것 같다.. 아쉬움이 많이 남는다.
이런 모델을 다른 사람의 도움 없이 스스로 만들 수 있었다는 것에 스스로 멋있다고 생각한다.
이런 간단하지만 스스로 뿌듯했던 과제는 프로젝트 카테고리에 남겨두도록 하겠다!
'프로젝트 > 머신러닝 과제' 카테고리의 다른 글
| [ML Project] Clustering, Regularization (0) | 2024.08.25 |
|---|---|
| [ML Project] EDA 데이터 분석 with SVM, PM, Decision Tree (2) | 2024.04.25 |