https://colab.research.google.com/drive/1EzrTi_8Il288fPBPhWchF22AZ0cjfVIq?usp=sharing
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
임의로 생성한 학과 학생들의 정보를 활용하여 해당 학생의 전공을 예측해 보자.
과제로 주어진 내용이긴 하지만 저의 주관적인 생각이 많이 들어가고 오직 파일만 주어진 과제였기에 project로 옮긴다.
같이 해보면서 코드를 이해해 보면 좋을 것 같아 공유합니다.
목표: SVM, Decision Tree 모델 활용하기!
• 입력 • 컴퓨터공학과 각 전공의 학생들의 정보가 담긴 csv 파일 “student-AI.csv”와 “studentComputer.csv”가 주어진다.
• 출력 • Csv 파일 안에 있는 학생들의 개인 정보들을 적절히 활용하여 해당 학생의 전공을 예측하자.
▪ dataset:
“student-AI.csv” ▪ 컴퓨터공학과 AI 전공 학생들에 대한 정보가 담겨 있습니다. ▪ 395 rows x 23 columns ▪ “student-Computer.csv” ▪ 컴퓨터공학과 컴퓨터 전공 학생들에 대한 정보가 담겨 있습니다. ▪ 649 rows x 23 columns
dataset preview:

참고사항:


COLAB에서 진행합니다.
1. 한글사용하기
# plot할 때 한글 사용 가능하게하기
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] =False
2. 파일 불러오기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# CSV 파일 불러오기
student_ai = pd.read_csv('student-AI.csv')
student_computer = pd.read_csv('student-Computer.csv')
# 전공 컬럼 추가
student_ai['major'] = 'AI'
student_computer['major'] = 'Computer'
3. 데이터 결합과 EDA 진행
# 데이터 병합
students = pd.concat([student_ai, student_computer], ignore_index=True)
if 'Unnamed: 0' in students.columns:
students = students.drop(['Unnamed: 0'], axis=1)
# 성별 분포 확인
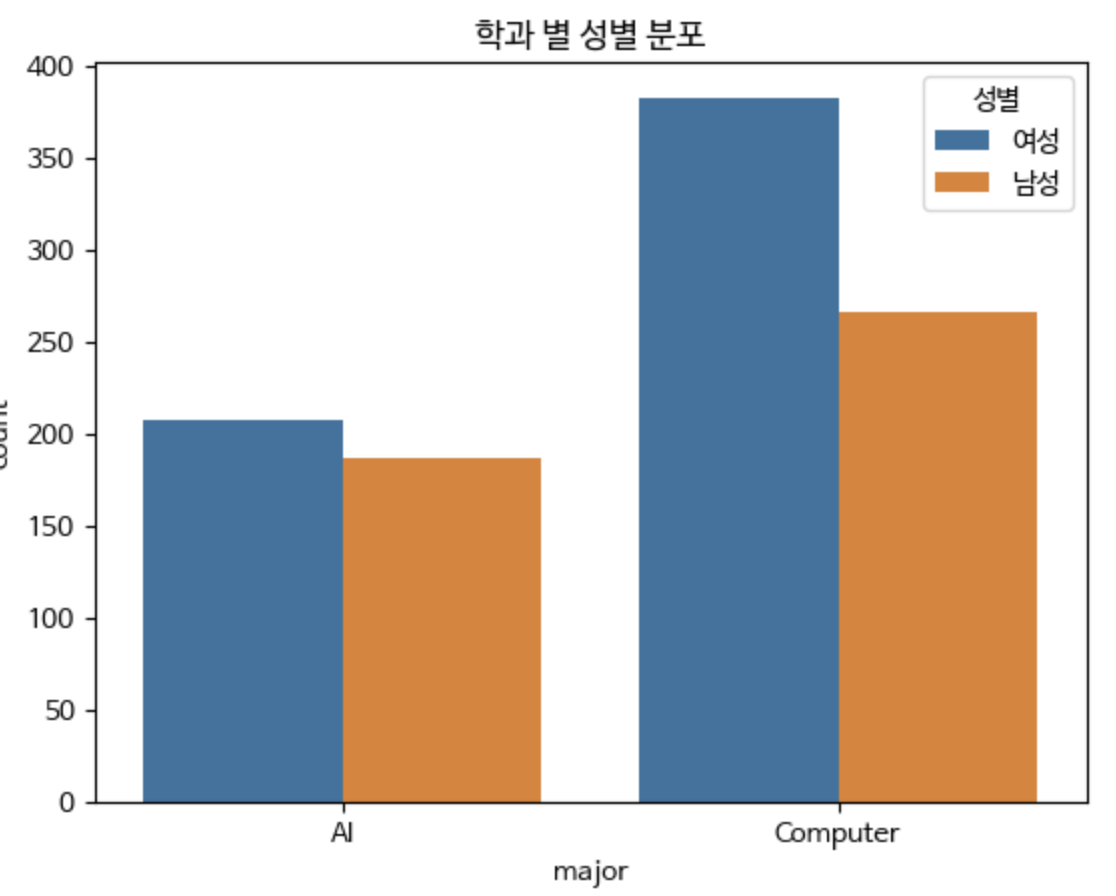
sns.countplot(x='major', hue = "sex", data=students)
plt.title('학과 별 성별 분포')
# 범례 레이블 변경
plt.legend(title='성별', labels=['여성', '남성'])
plt.show()
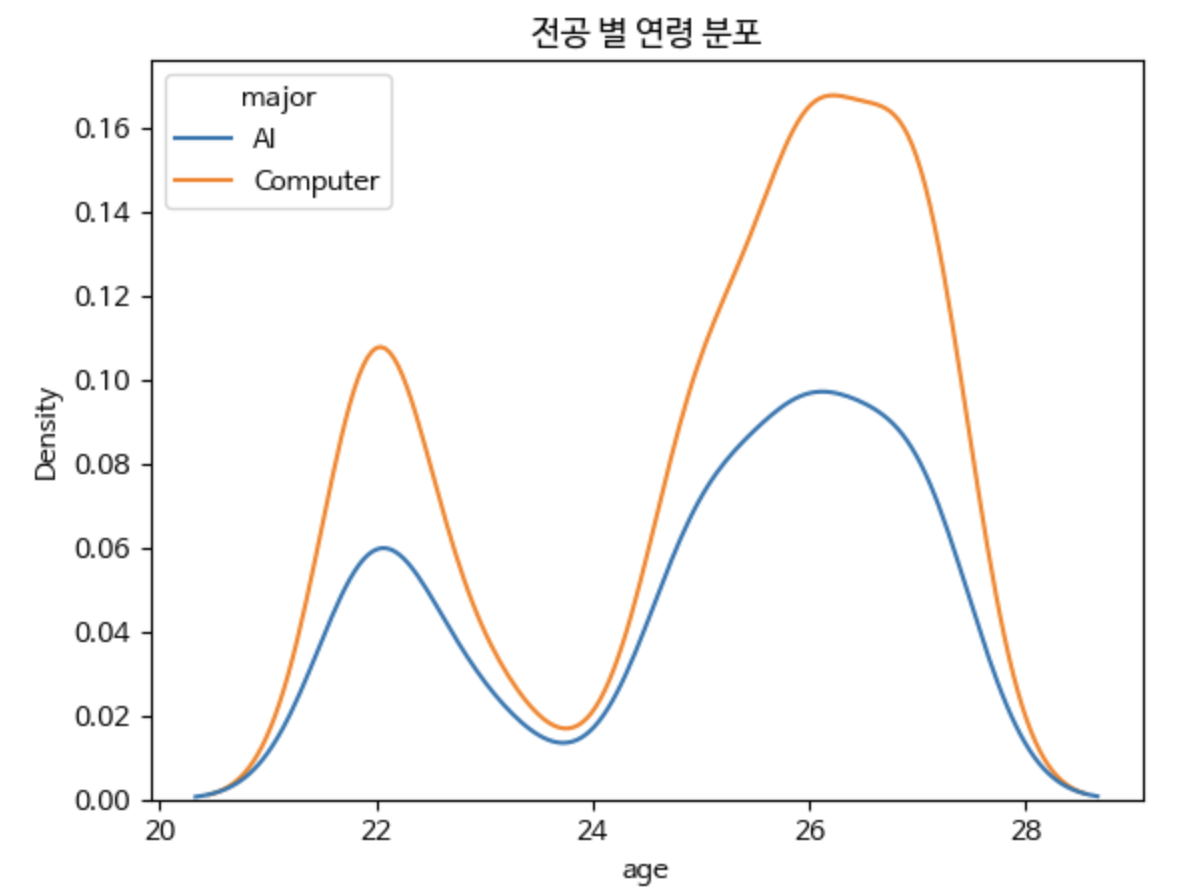
sns.kdeplot(data=students, x='age', hue='major')
plt.title('전공 별 연령 분포')
plt.show()
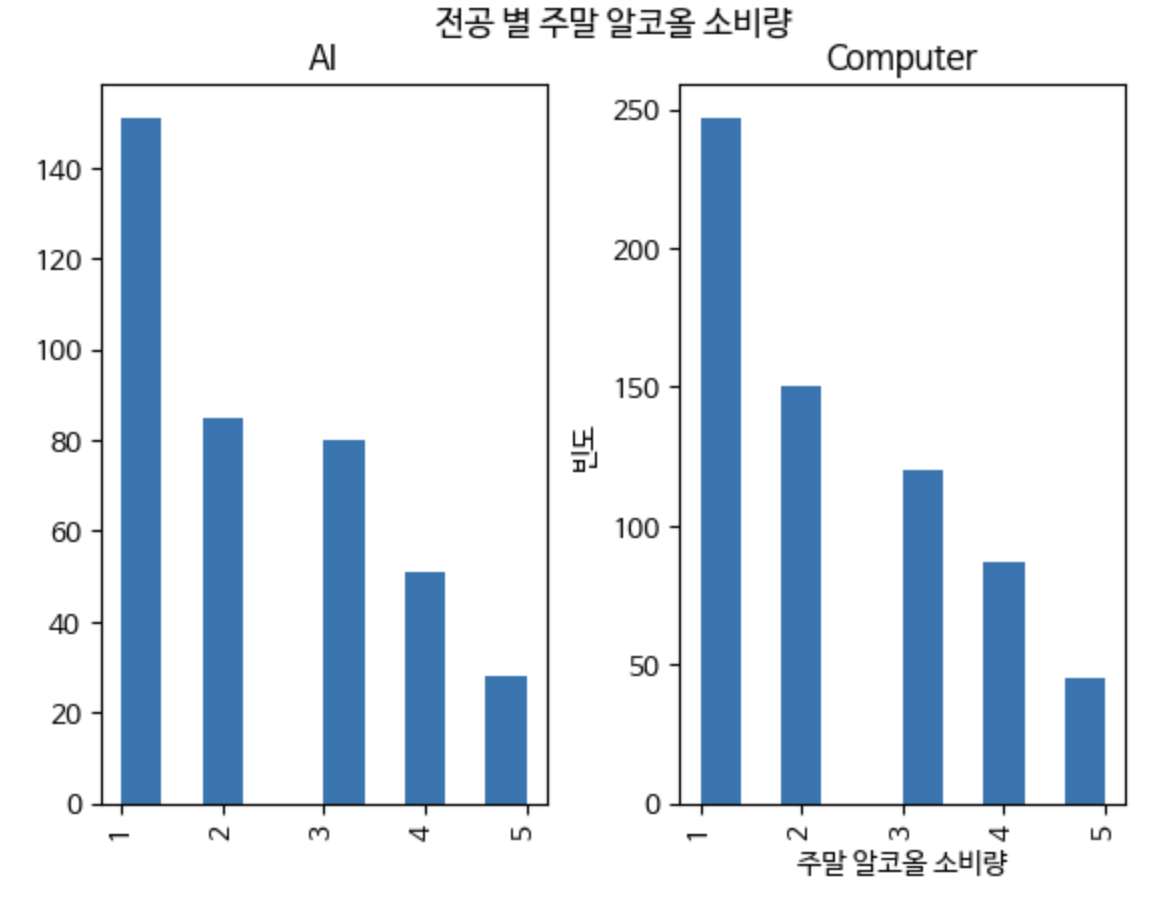
students['Walc'].hist(by=students['major'])
plt.suptitle('전공 별 주말 알코올 소비량')
plt.xlabel('주말 알코올 소비량')
plt.ylabel('빈도')
plt.show()
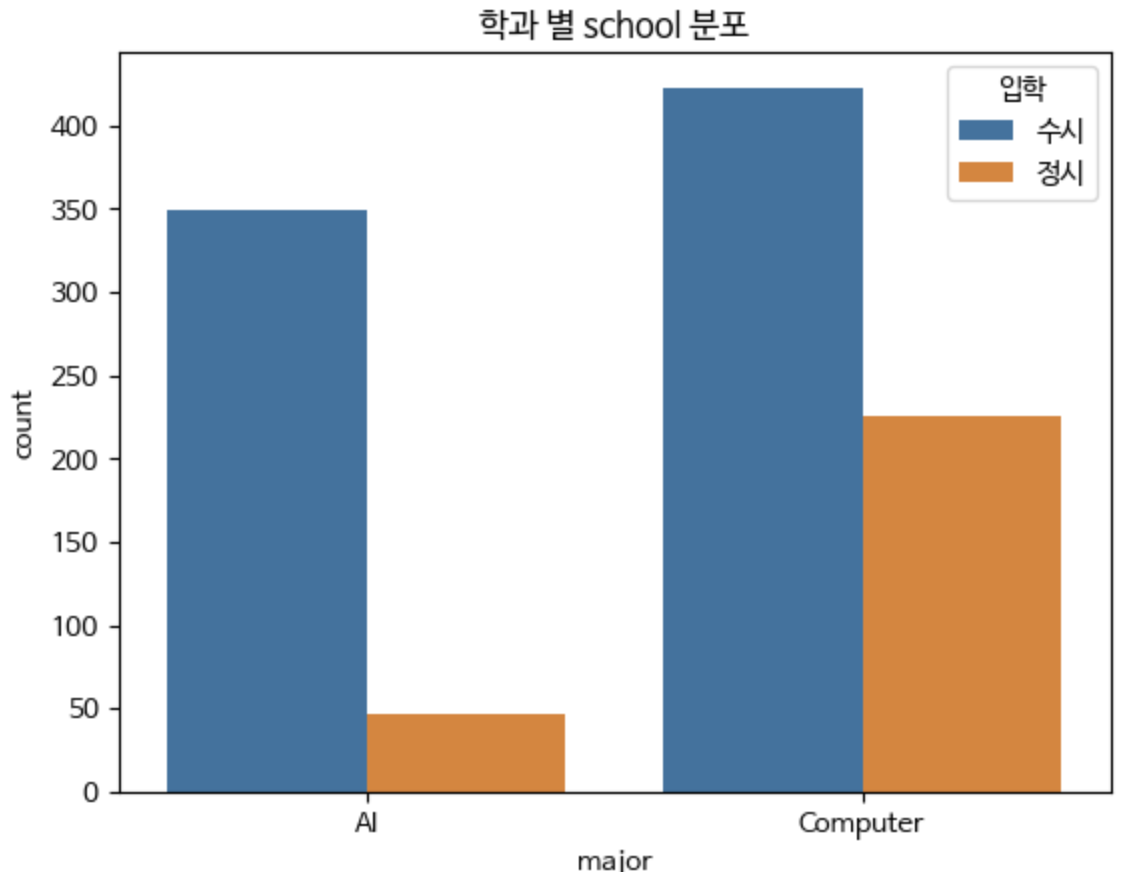
sns.countplot(x='major', hue = "school", data=students)
plt.title('학과 별 school 분포')
# 범례 레이블 변경
plt.legend(title='입학', labels=['수시', '정시'])
plt.show()
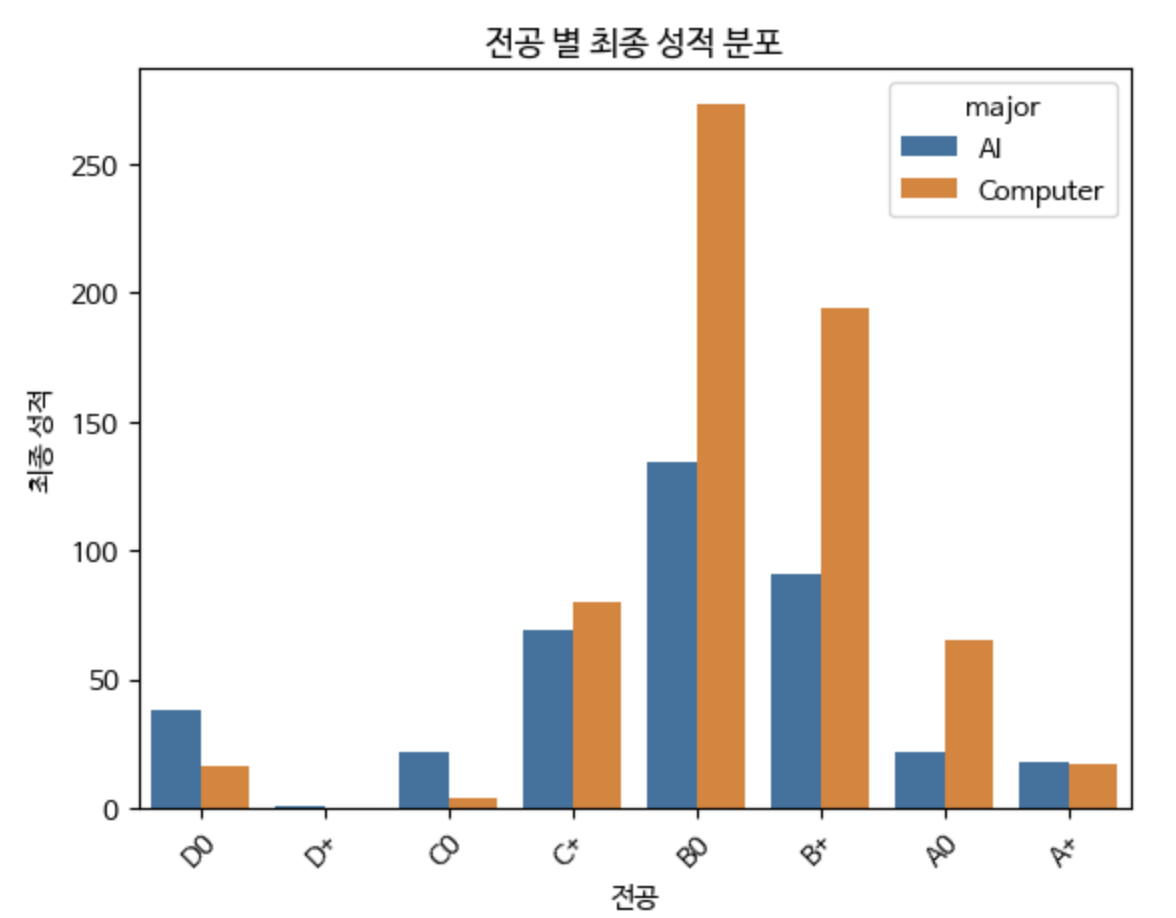
grade_order = ['D0', 'D+', 'C0', 'C+', 'B0', 'B+', 'A0', 'A+']
sns.countplot(x='G3', hue ="major", data=students, order=grade_order)
plt.title('전공 별 최종 성적 분포')
plt.xlabel('전공')
plt.ylabel('최종 성적')
plt.xticks(rotation=45) # x축 레이블 회전
plt.show()
sns.countplot(x='major', data=students)
plt.title('학과별 총 인원수')
plt.xlabel('전공')
plt.ylabel('인원수')
plt.xticks(rotation=45) # x축 레이블 회전
plt.show()
# 기타 필요한 EDA 진행
# 예: 인터넷 접근성, 가족 관계의 질, 학교 결석 횟수 등의 분포를 확인할 수 있습니다.
# 이진 카테고리형 변수 인코딩
students['sex'] = students['sex'].map({'F': 0, 'M': 1})
students['address'] = students['address'].map({'U': 0, 'R': 1})
# 기타 필요한 전처리 진행
EDA 결과:
4. Decision Tree로 구분하고 그려보기 모델 예측해 보기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import plot_tree
# CSV 파일 불러오기
student_ai = pd.read_csv('student-AI.csv')
student_computer = pd.read_csv('student-Computer.csv')
# keep_columns = ['G3', 'school', 'G1', 'G2', 'studytime', 'age', 'goout', 'sex', 'reason', 'Walc', 'failures', 'Fjob', 'famrel', 'Mjob', 'famsize', 'address', 'romantic', 'health']
# # 유지하고 싶은 컬럼을 제외한 나머지 컬럼 삭제
# student_ai = student_ai[keep_columns]
# student_computer = student_computer[keep_columns]
# 전공 컬럼 추가
student_ai['major'] = 'AI'
student_computer['major'] = 'Computer'
# 데이터 병합
students = pd.concat([student_ai, student_computer], ignore_index=True)
if 'Unnamed: 0' in students.columns:
students = students.drop(['Unnamed: 0'], axis=1)
# 범주형 데이터 인코딩
encoder = LabelEncoder()
categorical_cols = students.select_dtypes(include=['object']).columns
for col in categorical_cols:
students[col] = encoder.fit_transform(students[col])
# 특성과 레이블 분리
X = students.drop(['major'], axis=1)
y = students['major']
# 학습 및 테스트 세트 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Decision Tree 모델 학습
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 예측 및 정확도 평가
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f'모델 정확도: {accuracy * 100:.2f}%')
# Decision Tree 모델을 위한 하이퍼파라미터 그리드 생성 및 튜닝 (이부분 숫자를 조정해보거나 하이퍼파라미터를 추가해보며 튜닝해보기)
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': [None, 5, 10, 15, 20],
'min_samples_split': [2, 3, 4, 5, 10],
'min_samples_leaf': [1, 2, 3, 4, 5, 6]
}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=10, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 최적의 하이퍼파라미터 출력 및 최적 모델로 예측 및 평가
print(f"최적의 하이퍼파라미터: {grid_search.best_params_}")
best_model = grid_search.best_estimator_
predictions = best_model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f'최적 모델 정확도: {accuracy * 100:.2f}%')
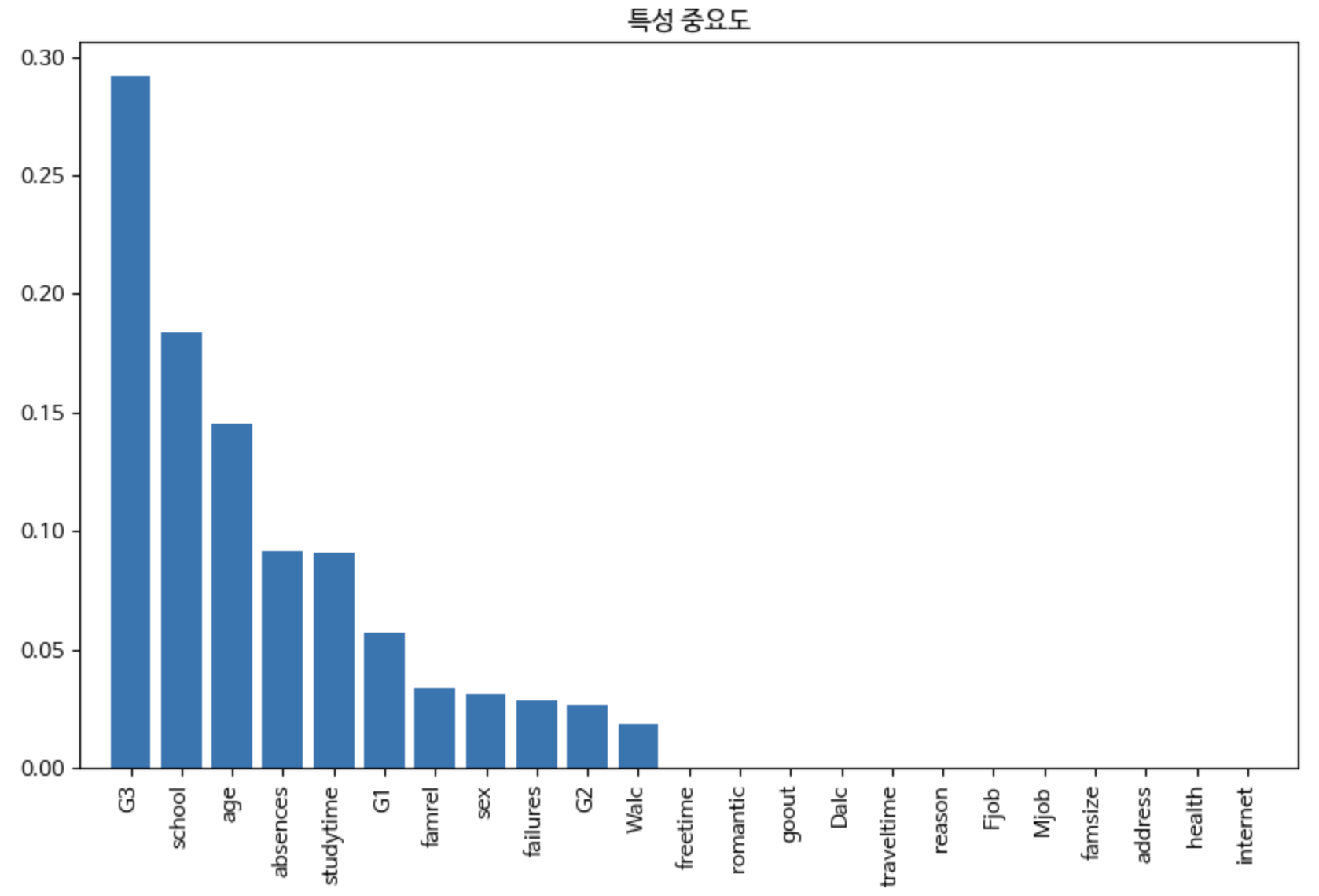
#특성 중요도 plot해보기
feature_importances = best_model.feature_importances_
features = X.columns
indices = np.argsort(feature_importances)[::-1]
plt.figure(figsize=(10,6))
plt.title('특성 중요도')
plt.bar(range(X.shape[1]), feature_importances[indices], align='center')
plt.xticks(range(X.shape[1]), [features[i] for i in indices], rotation=90)
plt.xlim([-1, X.shape[1]])
plt.show()
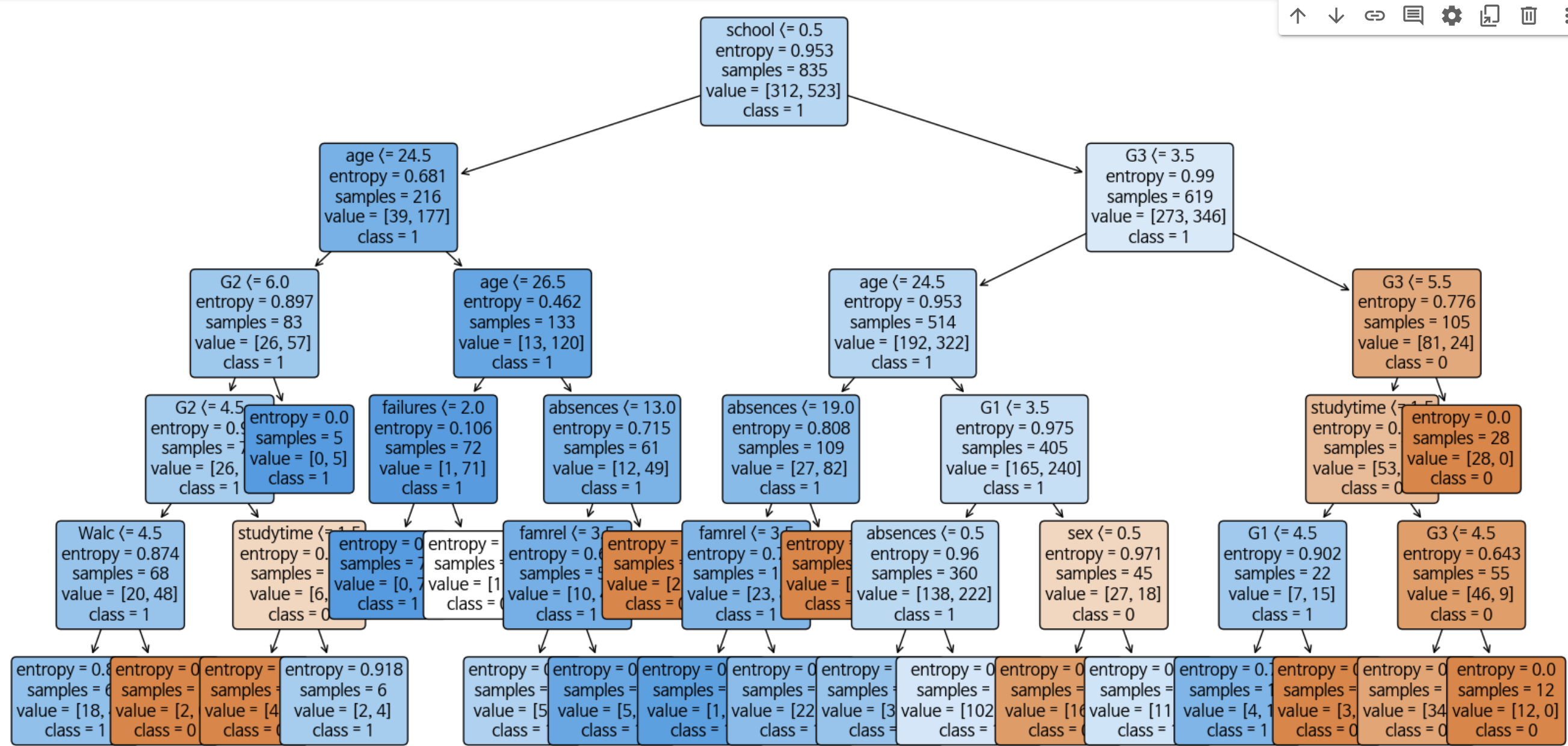
# plot tree 트리 시각화하여 확인하기
class_names_str = [str(cls) for cls in best_model.classes_]
plt.figure(figsize=(20, 10)) # 사이즈 조정
plot_tree(best_model,
feature_names=X.columns,
class_names=class_names_str,
filled=True,
rounded=True,
fontsize=12)
plt.show()모델 정확도: 57.42%
최적의 하이퍼파라미터: {'criterion': 'entropy', 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 4}
최적 모델 정확도: 69.38%
특성중요도, Tree
5. SVM모델 생성 후 평가
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import plot_tree
from sklearn.svm import SVC
# CSV 파일 불러오기
student_ai = pd.read_csv('student-AI.csv')
student_computer = pd.read_csv('student-Computer.csv')
# 전공 컬럼 추가
student_ai['major'] = 'AI'
student_computer['major'] = 'Computer'
# 데이터 병합
students = pd.concat([student_ai, student_computer], ignore_index=True)
# Unnamed: 0이라는 불필요한 데이터가 생성됐다면 제거하기
if 'Unnamed: 0' in students.columns:
students = students.drop(['Unnamed: 0'], axis=1)
# 범주형 데이터 인코딩
encoder = LabelEncoder()
categorical_cols = students.select_dtypes(include=['object']).columns
for col in categorical_cols:
students[col] = encoder.fit_transform(students[col])
# 특성과 레이블 분리
X = students.drop(['major'], axis=1)
y = students['major']
# 학습 및 테스트 세트 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# SVM 모델 학습
model = SVC()
model.fit(X_train, y_train)
# 예측 및 정확도 평가
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f'모델 정확도: {accuracy * 100:.2f}%')
# SVM 모델을 위한 하이퍼파라미터 그리드 생성 및 튜닝 (이부분 숫자를 조정해보거나 하이퍼파라미터를 추가해보며 튜닝해보기)
param_grid = {
'C': [0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10],
'kernel': ['rbf', 'sigmoid']
}
grid_search = GridSearchCV(SVC(), param_grid, cv=10, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
# 최적의 하이퍼파라미터 출력 및 최적 모델로 예측 및 평가
print(f"최적의 하이퍼파라미터: {grid_search.best_params_}")
best_model = grid_search.best_estimator_
predictions = best_model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f'최적 모델 정확도: {accuracy * 100:.2f}%')모델 정확도: 61.24%
최적의 하이퍼파라미터: {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
최적 모델 정확도: 63.64%
6. 제일 중요한 평가 후 모델 튜닝하기 (좀 더 좋은 모델로 진화시키기)
Decision Tree모델:
decision tree는 적용이 가능했고 하이퍼파라미터 튜닝을 하며 여러 번 도전해 보고 cross validation수도 조절하고 max_depth, min_samples_split, min_samples_leaf 수를 조절해 가며 최적의 하이퍼파라미터를 찾으려고 노력했습니다.
처음에 잘 모르고 시도했던 튜닝은 특성선택입니다.
특성중요도를 보니 특정 칼럼은 특성 중요도가 00 임을 보고 저 칼럼을 없애면 되겠구나! 하는 생각으로 데이터를 불러오고 저 특성을 없앴습니다.
그러고 나니 원래 모델 정확도가 57~60 정도 나왔었는데 저 특성을 제거하니 그래프는 깔끔해졌지만 모델 정확도는 49프로 까지 떨어졌습니다.
그 후 깨달음을 얻고 특성은 건드리지 않기로 하고
코드 부분 중
| # Decision Tree 모델을 위한 하이퍼파라미터 그리드 생성 및 튜닝 param_grid = { 'criterion': ['gini', 'entropy'], 'max_depth': [None, 5, 10, 15, 20], 'min_samples_split': [2, 3, 4, 5, 10], 'min_samples_leaf': [1, 2, 3, 4, 5, 6] } |
새로운 하이퍼파라미터: criterion를 추가하고 결과를 보고 최적의 숫자를
고르며 구간을 조정하고 제일 최적의 값들을 그리드에 넣어두었습니다.
cv값은 5부터 7, 10, 50을 해봤는데 계산 시간만 늘어나고 모델의 정확도에는 큰 영향을 미치지 않는 듯 보여서 추가 조정은 하지 않았습니다.
cv값이 100까지 커지게 되면 더 미세한 검증이 가능하고 일반화 성능의 정확한 추정이 가능하지만 계산 비용과 시간이 두 배 세배로 늘어나게 되고 데이터 불균형의 영향이 생기게 됩니다.
튜닝 과정은
| # | 모델 정확도 | 최적의 하이퍼파라미터 | 최적 모델 정확도 |
| 1 | 58.37% | {'max_depth': 10, 'min_samples_leaf': 4, 'min_samples_split': 2} | 64.11% |
| 2 | 57.89% | {'max_depth': 5, 'min_samples_leaf': 4, 'min_samples_split': 5} | 68.42% |
| 3 | 58.85% | {'criterion': 'entropy', 'max_depth': 5, 'min_samples_leaf': 1, 'min_samples_split': 2} | 69.38% |
세 번을 진행했는데 이게 최선인 것 같습니다..
어떤 튜닝을 더 해야 할지 몰라 차라리 다른 모델을 써보기로 했습니다.
그리고 추가로 tree의 모습을 보고 싶어 plot 해봤습니다.
처음엔 max_depth를 None로 했더니 너무 지저분했습니다.
나중에 제한해 두니 예쁜 트리가 나왔습니다.
SVM 모델:
SVM 모델에서는 시각화하기에는 특성이 너무 많아 차원이 높아 차원의 저주에 걸릴 수 있기 때문에 모델 정확도와 최적의 하이퍼파라미터만 찾아보도록 하겠습니다.
추가로 decision tree를 학습하고 보니 SVM모델은 그냥 코드 부분에서
| model = SVC() # 이 부분과 grid_search = GridSearchCV(SVC(), param_grid, cv=3, scoring='accuracy', n_jobs=-1) # 이 부분만 바뀜 |
위의 두 가지 부분만 바뀌고 크게 바뀐 게 없어서 구현하기 쉬웠던 것 같습니다.
1회 튜닝 시에는
| param_grid = { 'C': [1, 10], # 예: 더 적은 옵션 'gamma': [1, 0.1], # 예: 더 적은 옵션 'kernel': ['rbf', 'sigmoid'] # 예: 옵션 줄이기 } |
처음 모델을 학습시키는데 1010분 동안 학습시키고 있길래 놀래서 시간을 줄일 수 있는 방법은 다 찾아서 적용시켜 봤습니다.
2회 튜닝 시에는
| param_grid = { 'C': [0.01, 0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1, 10], 'kernel': ['rbf', 'sigmoid'] } |
c값과 gamma값을 좀 더 다양한 옵션을 주었습니다. 시간은 크게 늘어나지 않았습니다.
3회 튜닝 시에는
| param_grid = { 'C': [0.01, 0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1, 10], 'kernel': ['rbf', 'sigmoid', 'poly'] } |
kernel 옵션에 poly를 추가했습니다.
시간을 많이 잡아먹는 파라미터가 어떤 건가 했더니 poly였던 것 같습니다.
확실히 시간이 늘어났습니다. 소요시간은 5분입니다.
하지만 의외로 poly는 시간만 무지하게 잡아먹고 제일 최적모델 정확도가 높은 커널은 rbf였습니다.
4회 튜닝 시에는
| param_grid = { 'C': [0.01, 0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1, 10], 'kernel': ['rbf', 'sigmoid'] } grid_search = GridSearchCV(SVC(), param_grid, cv=10, scoring='accuracy', n_jobs=-1) |
poly를 삭제하고 cv값을 3 -> 10으로 향상했습니다..
튜닝 과정입니다.
| # | 모델 정확도 | 최적의 하이퍼파라미터 | 최적 모델 정확도 |
| 1 | 61.24% | {'C': 1, 'gamma': 1, 'kernel': 'sigmoid'} | 60.29% |
| 2 | 61.24% | {'C': 100, 'gamma': 0.001, 'kernel': 'rbf'} | 68.42% |
| 3 | 61.24% | {'C': 0.01, 'gamma': 0.01, 'kernel': 'poly'} | 64.59% |
| 4 | 61.24% | {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'} | 63.64% |
최종 결과는 의외로 2회 튜닝이 68.42%로 제일 높은 정확도를 보여주었습니다. cv값을 높이는 것도 오히려 정확도가 떨어질 수도 있다는 것을 알았습니다.
7. 마무리하며
Decision Tree모델보다는 모델보다는 SVM 모델이 조금 더 최적 모델 정확도가 높았고 반대로 SVM모델은 모델 정확도가 더 높았습니다. 각 모델별로 장단점이 있는 것 같습니다.
시각화를 해보며 눈으로 확인하는 건 tree가 편하긴 하지만 SVM이 능력이 더 좋다는 것을 알았습니다. 시험기간이 끝난 후 naive bayes 모델을 적용해 보며 재밌게 튜닝해 보며 성능을 더 끌어올려보겠습니다.
제가 끌어낸 정확도가 얼마큼 높은 건지 다른 수강생들은 어느 정도로 정확도가 나오는지 궁금하기도 하면서 정확도가 많이 낮게 나온 게 아닌가 싶기도 합니다. 하이퍼파라미터 튜닝 말고도 모델의 성능을 향상하는 방법이 많았고 모델 중 앙상블 모델이라는 것도 있었습니다. 추가로 학습해 보면 좋을 것 같습니다.
'프로젝트 > 머신러닝 과제' 카테고리의 다른 글
| [ML Project] Clustering, Regularization (0) | 2024.08.25 |
|---|---|
| [ML Project] Linear Regression을 활용한 주가 예측 모델 (0) | 2024.04.11 |