OCR(광학 문자 인식)이란 무엇인가?
광학 문자 인식(OCR)은 텍스트 이미지를 기계가 읽을 수 있는 텍스트 포맷으로 변환하는 과정입니다. 예를 들어 양식 또는 영수증을 스캔하는 경우 컴퓨터는 스캔본을 이미지 파일로 저장합니다. 이미지 파일에서는 텍스트 편집기를 사용하여 단어를 편집, 검색하거나 단어 수를 계산할 수 없습니다. 그러나 OCR을 사용하면 이미지를 텍스트 문서로 변환하여 내용을 텍스트 데이터로 저장할 수 있습니다.
여기저기 기술블로그에서 조각모음하여 하나로 모아보겠습니다~ 저의 의견과 코드는 소량 첨부 되었습니다.
사용해 볼 여러 가지 라이브러리
1. 테서랙트(tesseract)
2. EasyOCR
3. PaddleOCR
4. pororo
5. Google Vision ai
이런 것도 있다
1. Aspose
2. Naver Clova OCR
먼저 여기서 사용할 이미지파일은 다음과 같다.
후천성 면역 결핍증 환자의 추천식단 이미지를 글로 만들어 보겠다!
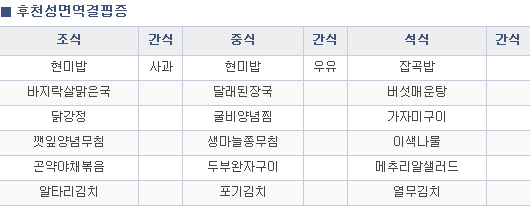
1. 테서랙트(tesseract)
Tesseract1는 오픈 소스 OCR (Optical Character Recognition) 엔진으로, 이미지에서 텍스트를 추출하는 데 사용됩니다. 원래 HP (Hewlett-Packard)에서 개발되었으며, 현재는 Google이 지원합니다. Tesseract는 다양한 운영 체제에서 사용할 수 있으며, 100개 이상의 언어를 지원합니다. Python에서는 Pytesseract 라이브러리 2를 통해 Tesseract의 기능을 활용할 수 있습니다.
코랩에서 바로 사용해 봅시다!
## 다운받기
!apt-get install -y tesseract-ocr
!apt-get install -y tesseract-ocr-kor
!pip install pytesseract# 테서랙트가 코랩에서 위치하는 곳 찾기
!which tesseract# pytesseract 사용을 위한 코드 추가
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'# 필요한 라이브러리 추가
import cv2
from matplotlib import pyplot as plt
import pytesseract
# 사용할 이미지 위치 주소 변수에 저장
image = r'./[여기다가 사진 이름 넣기]'
# 예시
# image = r'./1234.jpg'
# 이미지 파일 읽기
img = cv2.imread(image)
# 글자 추출 전처리를 위해 흑백으로 변환
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 흑백 처리한 이미지 확인
plt.imshow(gray)
plt.show()
# 한글과 영문 추출을 위한 config 내용 변수에 저장
config = ('-l kor+eng --oem 3 --psm 11')
# 이미지에서 글자 추출
output = pytesseract.image_to_string(gray, config=config)
# 추출한 글자 확인
print(output)
여기서는 전처리가 한번 된 후 진행이 된다 전처리 없이 진행하면 아래 사진처럼 결과가 나온다.

그렇다면 위의 코드처럼 살짝 전처리가 들어가면 어떻게 나올까?
이렇게 전처리가 되고

이런 식으로 나온다... 썩... 좋지는 않아 보인다?
굴비양념찜, 조석, 생마늘종무첨 성능이 좋다고 하기엔 애매하다!! 대신 사용법이 간단하다. 영어는 인식 잘할 듯?
2. EasyOCR
EasyOCR은 네이버 Clovaai의 CRAFT, deep-text-recognition benchmark을 기반으로 만든 오픈 소스 라이브러리다. 코드는 파이썬으로 작성되었고, 딥러닝을 기반으로 하여 텍스트를 이미지나 스캔한 문서에서 추출하는 기능을 제공한다.
출처: joongwon00.log
EasyOCR 깃허브: https://github.com/JaidedAI/EasyOCR
GitHub - JaidedAI/EasyOCR: Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chines
Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc. - JaidedAI/EasyOCR
github.com
코랩에서 사용하려면 그냥 코드만 쓰면 된다! 진짜 easy~
!pip install easyocrimport easyocr
reader = easyocr.Reader(['ko','en'])
results = reader.readtext('_F000104.jpg')
print(results)# 조금 보기 좋게 바꾸기
for i in range(len(results)):
print(results[i][1])
결과!!

이 정도면 나쁘지 않은 듯하다? 의외로 전처리한 테서렉트랑 비슷한 성능이다 이 정도면 "중"으로 주도록 하자 급하면 사용하면 좋을듯하다 빠른고 쉬운 게 진짜 장점
3. PaddleOCR
PaddleOCR은 중국의 인터넷 기업인 바이두(Baidu)가 만든 딥러닝 플랫폼 PaddlePaddle로 구현된 오픈 소스 OCR(Optical Character Recognition)입니다. 다양한 언어를 지원하며, 이미지와 문서에서 텍스트를 인식할 수 있습니다. PaddleOCR의 경량 모델은 14.8M로 매우 가벼워 모바일 등 다양한 플랫폼에서 사용이 가능합니다. 또한 중국어, 영어 이외에도 한국어를 포함하여 80개 이상의 다양한 언어를 지원합니다.
출처: https://alphalog.co.kr/249
[ OCR ] 한글 인식에 탁월한 성능, 적은 용량의 PaddleOCR 사용하기 - Python
PaddleOCR 이란? PaddleOCR은 중국의 인터넷 기업인 바이두(Baidu)가 만든 딥러닝 플랫폼 PaddlePaddle로 구현된 오픈 소스 OCR(Optical Character Recognition)입니다. 다양한 언어를 지원하며, 이미지와 문서에서 텍
alphalog.co.kr
거두절미 바로 사용해 보자
PaddleOCR도 사용법이 간단하다
!pip install paddleocr!pip install paddlepaddlefrom paddleocr import PaddleOCR
# 모델 셋업
ocr = PaddleOCR(lang="korean")
path = './_F000104.jpg'
result = ocr.ocr(path, cls=False)
print(result)# 보기 좋게 만들어보기
for i in range(len(result[0])):
print(result[0][i][1][0])
이렇게 하면 바로 결과가 보인다

뭔가 깔끔한 듯.. 이상한 듯.. 아직 마음에 들지 않는다~ 물론 개인마다 차이가 있으니 직접 모든 라이브러리를 하나씩 사용해 보고 고르도록 합시다
4. pororo

카카오 브레인에서 개발한 pororo 라이브러리 이름을 보니 귀엽게 잘 되지 않을까?
2021년 초에 카카오브레인(https://www.kakaobrain.com/)에서 다양한 한글 자연어 처리 작업을 위한 pororo('뽀로로'라고 읽습니다)(https://github.com/kakaobrain/pororo) 파이썬 라이브러리를 릴리스했습니다. pororo 라이브러리는 BERT, Transformer 등 파이토치로 구현된 최신 NLP 모델을 사용해 30여 가지의 자연어 처리 작업을 수행합니다. 여기에서는 이 중에 대표적인 몇 가지 작업에 대해서 알아보겠습니다. pororo 라이브러리가 수행할 수 있는 전체 작업 목록은 온라인 문서(https://kakaobrain.github.io/pororo/index.html)를 참고하세요.
pororo라이브러리는 pip 명령으로 간단히 설치할 수 있습니다. 현재는 파이썬 3.6 버전 이상과 파이토치 1.6 버전(CUDA 10.1)을 지원합니다.
놀랍게도 코랩에서는 이런 오류가 뜬다.
ERROR: Could not find a version that satisfies the requirement torch==1.6.0
(from versions: 1.11.0, 1.12.0, 1.12.1, 1.13.0, 1.13.1, 2.0.0, 2.0.1, 2.1.0,
2.1.1, 2.1.2, 2.2.0, 2.2.1, 2.2.2, 2.3.0, 2.3.1, 2.4.0, 2.4.1, 2.5.0, 2.5.1)
ERROR: No matching distribution found for torch==1.6.0
오류를 자세히 보면 pororo 라이브러리는 torch 1.6.x + cuda 10.1에서 만들어져서 다른 버전에서는 돌아가지 않는데
코랩에서는 1.11.0 이하의 버전은 지원하지 않는다! = 못써봄
혹시라도 시도라도 해 볼 사람들을 위해 윈도우에서 사용하는 pip install 명령어입니다~
# CUDA 10.1
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
추가로 혹시나 install이 되어서 ocr을 시도해보고 싶으신 분을 위해..
!pip install pororofrom pororo import Pororo
ocr = PororoOcr()
image_path = input("Enter image path: ")
text = ocr.run_ocr(image_path, debug=True)
print('Result :', text)
간단하게 사용해 보실 수 있습니다. (전 실패..)
그리고 다 하시고 다시 버전 원래대로 돌려놓읍시다!
!pip install torch
!pip install torchvision
!pip install opencv-python
5. Google Vision API OCR
매우 큰 단점 = 300 이상부턴 돈 들어 감ㅜ
이건 진짜 잘 설명해 주신 블로그를 남겨놓겠습니다. 정말 강추
https://davelogs.tistory.com/36
Google Cloud Vision API - OCR 사용하기 (1)
먼저 Google의 서비스를 이용해야 하므로 로그인부터 하고 진행한다. 1. Google Cloud 시작하기 먼저 다음 링크에서 Google Cloud에 가입하는 것부터 시작하자. cloud.google.com/gcp/ Google Cloud 컴퓨팅, 호스팅
davelogs.tistory.com
그대로 따라 해주십시오~ 새 프로젝트로 만드시는 거 잊지 마시고요 서비스 키 반드시 저장해 놓으시고요!
!pip install google-cloud-visionimport os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './[서비스키].json'from google.cloud import vision
import io
# Google Cloud Vision 클라이언트 초기화
client = vision.ImageAnnotatorClient()
# 이미지 파일 경로 설정
image_path = './_F000104.jpg'
# 이미지 파일을 읽고 Google Vision API에 전달
with io.open(image_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# OCR을 사용하여 이미지에서 텍스트 추출
response = client.text_detection(image=image)
texts = response.text_annotations
print(texts[0].description)# 텍스트를 줄 단위로 나누고 불필요한 부분 제거
lines = texts[0].description.split('\n')
cleaned_lines = [line for line in lines if line.strip()] # 빈 줄 제거
# 정리된 결과 출력
for line in cleaned_lines:
print(line)
결과!!

일단 성능이 너무 좋다! 앞선 다른 라이브러리들과는 많이 향상됐다. 단점은 300번 넘어가면 돈이 든다는 것이지만..
좌표값으로 다루기도 가능!
# 이렇게 출력하면 x, y 좌표값으로도 알려준다 행, 열방향으로 따로 읽고싶으면 사용하시면 됩니다.
print(texts[0])
이런 것도 있더라
1. Aspose (유료)
2. Naver Clova OCR (평이 굉장히 좋았습니다 가능하면 이거 사용해 보세요~)
결론
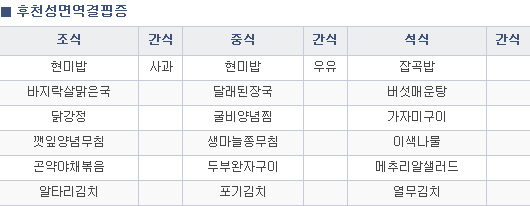
이 식단 사진을
['후천성면역결핍증', '조식', '간식', '중식', '간식', '석식', '간식', '현미밥', '사과', '현미밥', '우유', '잡곡밥', '바지락살맑은국', '달래된장국', '버섯매운탕', '닭강정', '굴비양념찜', '깻잎양념무침', '곤약야채볶음', '생마늘종무침', '가자미구이', '미색나물', '두부완자구이', '메추리알샐러드', '알타리김치', '포기김치', '열무김치']
네이버 클로버 OCR이 성능이 굉장히 좋다곤 하지만 회원가입하기가 귀찮아서..
역시 구글입니다. 없는 게 없더라고요 api키 발급받아보시고 한번 시도해 봅시다! 좋은 것 같습니다.
데이터 전처리 성공
이런 리스트 형태로 바꾸어 보았습니다
이제 모델 학습하러 가시죠...
OCR(광학 문자 인식)이란 무엇인가?
광학 문자 인식(OCR)은 텍스트 이미지를 기계가 읽을 수 있는 텍스트 포맷으로 변환하는 과정입니다. 예를 들어 양식 또는 영수증을 스캔하는 경우 컴퓨터는 스캔본을 이미지 파일로 저장합니다. 이미지 파일에서는 텍스트 편집기를 사용하여 단어를 편집, 검색하거나 단어 수를 계산할 수 없습니다. 그러나 OCR을 사용하면 이미지를 텍스트 문서로 변환하여 내용을 텍스트 데이터로 저장할 수 있습니다.
여기저기 기술블로그에서 조각모음하여 하나로 모아보겠습니다~ 저의 의견과 코드는 소량 첨부 되었습니다.
사용해 볼 여러 가지 라이브러리
1. 테서랙트(tesseract)
2. EasyOCR
3. PaddleOCR
4. pororo
5. Google Vision ai
이런 것도 있다
1. Aspose
2. Naver Clova OCR
먼저 여기서 사용할 이미지파일은 다음과 같다.
후천성 면역 결핍증 환자의 추천식단 이미지를 글로 만들어 보겠다!
1. 테서랙트(tesseract)
Tesseract1는 오픈 소스 OCR (Optical Character Recognition) 엔진으로, 이미지에서 텍스트를 추출하는 데 사용됩니다. 원래 HP (Hewlett-Packard)에서 개발되었으며, 현재는 Google이 지원합니다. Tesseract는 다양한 운영 체제에서 사용할 수 있으며, 100개 이상의 언어를 지원합니다. Python에서는 Pytesseract 라이브러리 2를 통해 Tesseract의 기능을 활용할 수 있습니다.
코랩에서 바로 사용해 봅시다!
## 다운받기
!apt-get install -y tesseract-ocr
!apt-get install -y tesseract-ocr-kor
!pip install pytesseract# 테서랙트가 코랩에서 위치하는 곳 찾기
!which tesseract# pytesseract 사용을 위한 코드 추가
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'# 필요한 라이브러리 추가
import cv2
from matplotlib import pyplot as plt
import pytesseract
# 사용할 이미지 위치 주소 변수에 저장
image = r'./[여기다가 사진 이름 넣기]'
# 예시
# image = r'./1234.jpg'
# 이미지 파일 읽기
img = cv2.imread(image)
# 글자 추출 전처리를 위해 흑백으로 변환
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 흑백 처리한 이미지 확인
plt.imshow(gray)
plt.show()
# 한글과 영문 추출을 위한 config 내용 변수에 저장
config = ('-l kor+eng --oem 3 --psm 11')
# 이미지에서 글자 추출
output = pytesseract.image_to_string(gray, config=config)
# 추출한 글자 확인
print(output)
여기서는 전처리가 한번 된 후 진행이 된다 전처리 없이 진행하면 아래 사진처럼 결과가 나온다.
그렇다면 위의 코드처럼 살짝 전처리가 들어가면 어떻게 나올까?
이렇게 전처리가 되고
이런 식으로 나온다... 썩... 좋지는 않아 보인다?
굴비양념찜, 조석, 생마늘종무첨 성능이 좋다고 하기엔 애매하다!! 대신 사용법이 간단하다. 영어는 인식 잘할 듯?
2. EasyOCR
EasyOCR은 네이버 Clovaai의 CRAFT, deep-text-recognition benchmark을 기반으로 만든 오픈 소스 라이브러리다. 코드는 파이썬으로 작성되었고, 딥러닝을 기반으로 하여 텍스트를 이미지나 스캔한 문서에서 추출하는 기능을 제공한다.
출처: joongwon00.log
EasyOCR 깃허브: https://github.com/JaidedAI/EasyOCR
GitHub - JaidedAI/EasyOCR: Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chines
Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc. - JaidedAI/EasyOCR
github.com
코랩에서 사용하려면 그냥 코드만 쓰면 된다! 진짜 easy~
!pip install easyocrimport easyocr
reader = easyocr.Reader(['ko','en'])
results = reader.readtext('_F000104.jpg')
print(results)# 조금 보기 좋게 바꾸기
for i in range(len(results)):
print(results[i][1])
결과!!
이 정도면 나쁘지 않은 듯하다? 의외로 전처리한 테서렉트랑 비슷한 성능이다 이 정도면 "중"으로 주도록 하자 급하면 사용하면 좋을듯하다 빠른고 쉬운 게 진짜 장점
3. PaddleOCR
PaddleOCR은 중국의 인터넷 기업인 바이두(Baidu)가 만든 딥러닝 플랫폼 PaddlePaddle로 구현된 오픈 소스 OCR(Optical Character Recognition)입니다. 다양한 언어를 지원하며, 이미지와 문서에서 텍스트를 인식할 수 있습니다. PaddleOCR의 경량 모델은 14.8M로 매우 가벼워 모바일 등 다양한 플랫폼에서 사용이 가능합니다. 또한 중국어, 영어 이외에도 한국어를 포함하여 80개 이상의 다양한 언어를 지원합니다.
출처: https://alphalog.co.kr/249
[ OCR ] 한글 인식에 탁월한 성능, 적은 용량의 PaddleOCR 사용하기 - Python
PaddleOCR 이란? PaddleOCR은 중국의 인터넷 기업인 바이두(Baidu)가 만든 딥러닝 플랫폼 PaddlePaddle로 구현된 오픈 소스 OCR(Optical Character Recognition)입니다. 다양한 언어를 지원하며, 이미지와 문서에서 텍
alphalog.co.kr
거두절미 바로 사용해 보자
PaddleOCR도 사용법이 간단하다
!pip install paddleocr!pip install paddlepaddlefrom paddleocr import PaddleOCR
# 모델 셋업
ocr = PaddleOCR(lang="korean")
path = './_F000104.jpg'
result = ocr.ocr(path, cls=False)
print(result)# 보기 좋게 만들어보기
for i in range(len(result[0])):
print(result[0][i][1][0])
이렇게 하면 바로 결과가 보인다
뭔가 깔끔한 듯.. 이상한 듯.. 아직 마음에 들지 않는다~ 물론 개인마다 차이가 있으니 직접 모든 라이브러리를 하나씩 사용해 보고 고르도록 합시다
4. pororo
카카오 브레인에서 개발한 pororo 라이브러리 이름을 보니 귀엽게 잘 되지 않을까?
2021년 초에 카카오브레인(https://www.kakaobrain.com/)에서 다양한 한글 자연어 처리 작업을 위한 pororo('뽀로로'라고 읽습니다)(https://github.com/kakaobrain/pororo) 파이썬 라이브러리를 릴리스했습니다. pororo 라이브러리는 BERT, Transformer 등 파이토치로 구현된 최신 NLP 모델을 사용해 30여 가지의 자연어 처리 작업을 수행합니다. 여기에서는 이 중에 대표적인 몇 가지 작업에 대해서 알아보겠습니다. pororo 라이브러리가 수행할 수 있는 전체 작업 목록은 온라인 문서(https://kakaobrain.github.io/pororo/index.html)를 참고하세요.
pororo라이브러리는 pip 명령으로 간단히 설치할 수 있습니다. 현재는 파이썬 3.6 버전 이상과 파이토치 1.6 버전(CUDA 10.1)을 지원합니다.
놀랍게도 코랩에서는 이런 오류가 뜬다.
ERROR: Could not find a version that satisfies the requirement torch==1.6.0
(from versions: 1.11.0, 1.12.0, 1.12.1, 1.13.0, 1.13.1, 2.0.0, 2.0.1, 2.1.0,
2.1.1, 2.1.2, 2.2.0, 2.2.1, 2.2.2, 2.3.0, 2.3.1, 2.4.0, 2.4.1, 2.5.0, 2.5.1)
ERROR: No matching distribution found for torch==1.6.0
오류를 자세히 보면 pororo 라이브러리는 torch 1.6.x + cuda 10.1에서 만들어져서 다른 버전에서는 돌아가지 않는데
코랩에서는 1.11.0 이하의 버전은 지원하지 않는다! = 못써봄
혹시라도 시도라도 해 볼 사람들을 위해 윈도우에서 사용하는 pip install 명령어입니다~
# CUDA 10.1
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
추가로 혹시나 install이 되어서 ocr을 시도해보고 싶으신 분을 위해..
!pip install pororofrom pororo import Pororo
ocr = PororoOcr()
image_path = input("Enter image path: ")
text = ocr.run_ocr(image_path, debug=True)
print('Result :', text)
간단하게 사용해 보실 수 있습니다. (전 실패..)
그리고 다 하시고 다시 버전 원래대로 돌려놓읍시다!
!pip install torch
!pip install torchvision
!pip install opencv-python
5. Google Vision API OCR
매우 큰 단점 = 300 이상부턴 돈 들어 감ㅜ
이건 진짜 잘 설명해 주신 블로그를 남겨놓겠습니다. 정말 강추
https://davelogs.tistory.com/36
Google Cloud Vision API - OCR 사용하기 (1)
먼저 Google의 서비스를 이용해야 하므로 로그인부터 하고 진행한다. 1. Google Cloud 시작하기 먼저 다음 링크에서 Google Cloud에 가입하는 것부터 시작하자. cloud.google.com/gcp/ Google Cloud 컴퓨팅, 호스팅
davelogs.tistory.com
그대로 따라 해주십시오~ 새 프로젝트로 만드시는 거 잊지 마시고요 서비스 키 반드시 저장해 놓으시고요!
!pip install google-cloud-visionimport os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './[서비스키].json'from google.cloud import vision
import io
# Google Cloud Vision 클라이언트 초기화
client = vision.ImageAnnotatorClient()
# 이미지 파일 경로 설정
image_path = './_F000104.jpg'
# 이미지 파일을 읽고 Google Vision API에 전달
with io.open(image_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# OCR을 사용하여 이미지에서 텍스트 추출
response = client.text_detection(image=image)
texts = response.text_annotations
print(texts[0].description)# 텍스트를 줄 단위로 나누고 불필요한 부분 제거
lines = texts[0].description.split('\n')
cleaned_lines = [line for line in lines if line.strip()] # 빈 줄 제거
# 정리된 결과 출력
for line in cleaned_lines:
print(line)
결과!!
일단 성능이 너무 좋다! 앞선 다른 라이브러리들과는 많이 향상됐다. 단점은 300번 넘어가면 돈이 든다는 것이지만..
좌표값으로 다루기도 가능!
# 이렇게 출력하면 x, y 좌표값으로도 알려준다 행, 열방향으로 따로 읽고싶으면 사용하시면 됩니다.
print(texts[0])
이런 것도 있더라
1. Aspose (유료)
2. Naver Clova OCR (평이 굉장히 좋았습니다 가능하면 이거 사용해 보세요~)
결론
이 식단 사진을
['후천성면역결핍증', '조식', '간식', '중식', '간식', '석식', '간식', '현미밥', '사과', '현미밥', '우유', '잡곡밥', '바지락살맑은국', '달래된장국', '버섯매운탕', '닭강정', '굴비양념찜', '깻잎양념무침', '곤약야채볶음', '생마늘종무침', '가자미구이', '미색나물', '두부완자구이', '메추리알샐러드', '알타리김치', '포기김치', '열무김치']
네이버 클로버 OCR이 성능이 굉장히 좋다곤 하지만 회원가입하기가 귀찮아서..
역시 구글입니다. 없는 게 없더라고요 api키 발급받아보시고 한번 시도해 봅시다! 좋은 것 같습니다.
데이터 전처리 성공
이런 리스트 형태로 바꾸어 보았습니다
이제 모델 학습하러 가시죠...